|
|
|
|||
Department of Agriculture and Food Systems
|
||||
|
||||
|
|
|
|||
Department of Agriculture and Food Systems
|
||||
|
||||
|
|
Australasian Agribusiness Review - Vol. 13 - 2005Paper 14 Rainfall and Farm Efficiency Measurement for Broadacre Agriculture in South-Western Australia
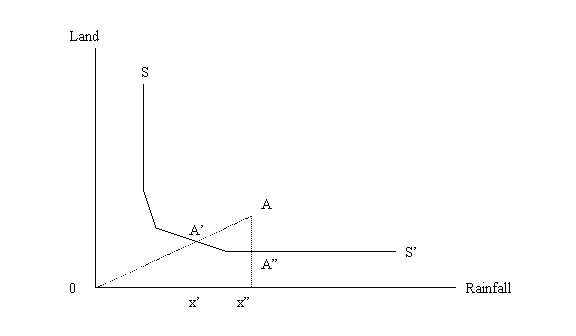
Ben Henderson, School of Agriculture and Resource Economics, University of Western Australia. Ross Kingwell, School of Agriculture and Resource Economics, University of Western Australia and Department of Agriculture, Western Australia. AbstractFew studies of farm technical efficiency consider differences in the physical environments of farms. This study examines rain-fed broadacre agriculture and shows how neglect of rainfall differences between farms affects measures of farm technical efficiency (TE). Applying data envelopment analysis (DEA) to a sample of broadacre farms, TE measures unconfounded by rainfall variation are generated by specifying rainfall as a non-discretionary production input in an input-orientated DEA model. These unconfounded TE measures are compared to other TE measures generated by a conventional DEA model that does not explicitly include rainfall. The conventional DEA model reports lower levels of technical efficiency, particularly for farms with below average rainfall, suggesting that measurement of TE should, where possible, include environmental effects such as rainfall. 1. IntroductionWhile a large number of studies have employed Data Envelopment Analysis (DEA) for the purpose of examining technical efficiency (TE) in agricultural industries both in Australia and internationally (e.g. Chavas and Aliber 1993; Piot-Lepetit et al. 1997; Rao and Coelli 1998; Fraser and Cordina 1999), few have considered the impact on these performance measures of variations in the physical quality of farm environments. One exception in the Australian agricultural literature is the study by Chapman et al. (1999), where DEA was used to examine productivity variation amongst a group of Australian wool farmers, and its relationship with seasonal rainfall. This study relied on spatial information to inspect the correlation between farm productivity and rainfall and identified a positive relationship between the two. However, rainfall was not explicitly accounted for in the derivation of the performance measures. Piesse et al. (1996) examined the relationship between DEA performance measures and rainfall for a group of South African maize farms. The impact of drought on TE was examined. Data from a non-drought year and drought year were pooled and as expected, observations from the drought year were found to be more inefficient. Again, rainfall variation was not explicitly considered in deriving the performance measures. DEA like other frontier techniques, such as stochastic frontier analysis, creates an efficient frontier from actual observations that are assumed to characterise the technology of the agricultural industry under investigation. A farm’s performance is rated according to its distance from the efficient frontier. Depending on the orientation of the DEA model, a farm’s TE score indicates either the extent to which it can increase output without additional inputs, or the extent to which input usage can contract while maintaining constant output. An output-oriented model measures the former, while an input-oriented model measures the latter. Whichever DEA model is specified, the resulting TE measure is considered to be one measure of the managerial ability of the farm operator. However, the confidence with which variation in TE can be attributed to variation in managerial ability depends on the accuracy and quality of the data used, including the extent to which account is taken of environmental variations that affect farm production. Failure to account for this variation can provide misleading TE estimates, which degrade the usefulness of frontier efficiency applications. The extent of bias or error introduced through failure to account for environmental influences can be substantial as shown by O’Donnell and Griffiths (2005) when reporting state-contingent production frontiers for Philippine rice growers. They found that when environmental variability was not explicitly considered TE estimates were halve those estimated when environmental variability was included. While most DEA efficiency studies on agricultural industries acknowledge the need to account for variations in the physical environment of farms when deriving efficiency measures, very few go further than grouping farms into arbitrarily assigned groups, considered homogenous in environment due to their proximity to one another. Dyson (2001) lists the typical problems and mistakes encountered and made by DEA practitioners. He identifies the non-homogeneity of firm environments as a major pitfall, stating that the environment of sample units is rarely homogenous and that failure to account for environmental differences between firms biases performance measures where the environment has a direct impact on performance. This paper reports the spread of TE amongst a sample of Western Australian broadacre farms, while explicitly accounting for variation in farm annual rainfall. More specifically, this study examines the impact on TE of accounting for rainfall variation between farms. Rainfall is the only environmental variable considered because, compared with other environmental variables such as soil quality or air temperature, it is the main determinant of yield in rain-fed or dryland Western Australian broadacre agriculture (DAWA, 1990; AWA, 2000). The following section draws on the DEA literature to outline some main approaches to accounting for environmental variation, while identifying some of the problems inherent in each approach. Following this are descriptions of the model and data used in this study. Results are outlined in section 5 and finally a set of conclusions and caveats are presented. 2. Accounting for Variation in EnvironmentFarrell (1957), in his pioneering paper on frontier efficiency measurement, warned of the need to account for what he described as ‘quasi-variables’, which included air and water quality, climate and location. Failure to account for these quasi-variables or environmental variables, he warned, would upwardly (downwardly) bias the efficiency scores of those firms with more (less) favourable production environments. Farrell suggested that variation in environment could be accounted for by dividing the observations into groups homogenous in the environmental variable under consideration and then constructing separate frontiers for each group. While this may generate efficiency scores free from the bias described above, dividing the sample into smaller sub samples can significantly reduce sample size, increasing the dimensionality of DEA models, and thus reduce their discriminating power. Coelli et al. (1998) outlined a few approaches for dealing with environmental variables. One is an approach similar to that suggested by Farrell, but with an additional step. Again it involves dividing the sample into sub-groups homogenous in the environmental variable then, following Charnes et al. (1981), solving separate DEA programs and projecting the scores onto their respective frontiers. The projected scores are then used to solve a single DEA program with the resulting mean efficiency scores from each sub-sample being compared to quantify the influence of the environmental variable on efficiency. However, like Farrell's approach, this variant also suffers from restricting the size of the sample set in the first stage and should, therefore, be avoided unless a large number of observations are available. Also, while this approach is suitable when the environmental variable is categorical and its direction of influence is unknown (e.g. location), it cannot handle continuous environmental variables such as rainfall. Another approach outlined in Coelli et al. (1998) directly incorporates the environmental variables into the production function either as input variables, if their impact on TE is positive and if an input orientation is used, or as output variables, if their impact on TE is negative and an output orientation is used. In this study of broadacre farms in south-western Australia, rainfall is included as an input variable in an input-orientated DEA model. Rainfall is a main determinant of crop and pasture yields in dryland farming systems and significantly and positively influences farm TE (Henderson, 2002). Including an environmental variable as a conventional input necessitates making the assumption that it can be reduced or increased like all other inputs and, in effect, is under the control of the farmer. However, this is untrue for environmental variables. For example, a farmer has no control over the amount of available rainfall that underpins rain-fed crop and pasture production. The exogenous nature of environmental variables such as rainfall requires them to be directly included as a non-discretionary or fixed inputs. Figure 1 demonstrates the difference between radial efficiency measurement, where rainfall is considered to be under the control of the farm manager, and a non-radial efficiency measurement where the rainfall variable is fixed.
Figure 1 Radial and non-radial measures of efficiency
If rainfall is considered to be under the control of the farm manager, the DEA problem seeks to radially contract farm A’s input use to point A’ on the efficient frontier, SS’. If, however, rainfall is treated as a non-discretionary input, point A’’ represents the technically efficient point of production. While this approach adequately copes with continuous environmental variables such as rainfall, it still suffers from restricting the size of the reference set, because it requires that farms are only compared to a (theoretical) frontier farm with an equal or less favourable environment. Another criticism leveled at this approach is that the direction of influence and significance of the environmental variable must first be known (Fried et al., 1999). An alternative approach outlined in Coelli et al. (1998) involves using a two-stage regression model, whereby the TE scores, estimated first using DEA, are regressed on the environmental variable(s) so that the sign, magnitude and level of significance of the coefficients can be used to determine the strength of the relationship(s). If the coefficient is significant, its value can then be used to ‘correct’ the efficiency scores so they correspond to a common level of environment. This approach has a few advantages over those discussed above. Firstly, the direction of influence does not need to be known, and the variables may be included as continuous or categorical variables. Secondly, the approach can cope with more than one environmental variable. Despite these advantages, the effectiveness of this approach can be reduced considerably if the production input variables are highly correlated with the environmental variables required in the second stage. The two-stage approach is also criticised for only considering radial efficiency and ignoring the information contained in slacks (Fried et al., 1999). Fried et al. (1999) describe an extension of the frontier separation and two-stage regression procedures outlined above. Their approach uses four stages to derive measures of ‘pure’ managerial inefficiency. The first stage solves a conventional DEA model with traditional inputs and outputs. In the second stage, a system of equations is used which consists of a dependent variable equal to the sum of radial and non-radial slacks, and identifies variation attributable to external environmental influences. Parameters from the second stage are then used to predict the total input slack associated with specific levels of the environmental variable. These values are then used to derive adjusted input data that incorporate the impact of environmental variation. Farms that operate in more favourable environments have their input levels raised, so that they do not receive inflated TE ratings. Finally, the DEA programme is re-run with the adjusted production inputs, which is said to isolate the managerial component of inefficiency by providing measures of TE uncorrupted by exogenous features of the farms' operating environments. In this paper, the approach adopted directly incorporates the environmental variable (rainfall) into the production function as a non-discretionary input variable in a single stage. This approach appears to be the natural choice when dealing with rainfall due to its direct influence on crop and pasture yields. A reasonably large data set and a small number of variables are used in this study (see section 4). Hence, the addition of an extra input into the DEA model was considered to have a negligible impact on reducing the discriminating power of the model. Henderson (2002) used the same data set as this study and found that rainfall was related positively and significantly to TE at the 5 per cent level of significance. 3. Model DescriptionTwo DEA models are used in the analysis. Firstly, a conventional input-orientated DEA with variable returns to scale (VRS) is solved. Then a second model, which is identical to the first except that it includes rainfall directly as a non-discretionary production input, is solved. The TE scores derived from each of these models are then compared to assess to impact on TE of accounting for annual rainfall. Both DEA models were solved using the DEAP 3.0[1] software program which permits the inclusion of non-discretionary inputs. Below is a mathematical representation of the conventional DEA problem described above. This model is the same as that proposed by Banker et al. (1984), using an input orientation: Assume there are data on K inputs and I outputs for each of N farms. For the farm n’ these are represented by the vectors xkn’ for k =1,…, K inputs, and yin’ for i = 1,…, I outputs. Minimise β (1) (λ1,…,λN, β) Subject to:
β is minimised for each farm, which contracts the input vectors of inefficient farms bringing them onto the frontier (see figure 1). The λs are weights that determine the point on the frontier where inefficient farms should be producing. Thus, the hypothetical point of maximum efficiency for an inefficient farm is determined by the weighted average of a combination of efficient farms making up the frontier. Looking at the constraints in equation (1): The first constraint ensures that each n’s output is no larger than the maximum linear combination of the i-th output of the farms making up the frontier. The second constraint ensures that firm n’s k-th input will be scaled down by β to an input level no greater than that created by the weighted linear combination of the k-th input used by all farms. The β will satisfy 1 ≥ β > 0 and it represents the TE score for farm n, where a value of one indicates a fully efficient farm. 1 - β represents the proportional reduction in observed input possible for farm n, with its output levels held constant. To obtain a TE value for each farm, the linear programming problem must be solved N-times for each of the N farms. Below is a mathematical representation of the DEA model that includes rainfall directly as a non-discretionary production input. Minimise θ (2) (λ1,…,λN, θ) Subject to:
The only difference between equation (2) and equation (1) is the addition of the third constraint. This represents the non-discretionary environmental variable, rainfall, which the farmer has no control over. It also ensures that inefficient farms are only compared to farms with less or equal rainfall. Because the extra constraint in equation (2) restricts the size of the reference set of each farm more than the model that does not include rainfall (equation (1)), θ must be greater than or equal to β for each farm. More generally, the farm TE scores reported by equation (2) must be greater than or equal to than those from equation (1). 4. Data and estimationMembers of the Australian Association of Agricultural Consultants (WA branch) were approached and several kindly supplied farm data that preserved the anonymity of their clients. Data from over 100 farmers for up to 5 consecutive years were initially gathered. Farms in this region have mixed enterprises of crops and livestock (see table 1). The data were detailed records of each farm's physical and financial items. Using ancillary data, indexing techniques and after clarifying data for some individual farms, each farm's data in each year were re-expressed as a series of input and output indexes. Missing data precluded the use of all of the observations in each year, leaving a slightly reduced sample of 93 farms over 3 consecutive years. The DEA models comprised crops (O1) and livestock (O2) as output variables and capital (I1), labour (I2), materials (I3), services (I4) and rainfall (I5) as input variables.[2] Summary statistics for these variables are listed in table 1. Over the period the average value of cropping enterprises rose, while the average value of livestock enterprises declined. The reduction in the value of the livestock enterprises was due mainly to a switch of land resources into more cropping and a reduction in the size of the sheep flock. ABARE (1999) reported these same enterprise trends for the central and southern broadacre farming regions of Western Australia. There was a large variation in the size of farms in the sample, leading to relatively large coefficients of variation in most input and output categories. Table 1 Summary statistics for the value of inputs and outputs in each year
To derive the input and output categories required aggregation. For example, crop output was based on the aggregation of data involving several crop types including wheat, barely, oats, lupins, canola and pulses. All of the variables were aggregated using the Fisher quantity index, which was chosen because it possesses many desirable statistical and economic theoretic properties that other indices do not. These include the duality between the Fisher price and quantity indices and its dimension invariance (Coelli et al., 1998). One important property, however, that the Fisher index does not possess is transitivity which ensures internal consistency. Consequently, the EKS method (Elteto-Koves, 1964; Szulc, 1964) was used to convert the Fisher Index into a transitive index. The TFPIP 1.0[4] computer program was used to generate the indexes. The data and derivation for each variable (crops (O1), livestock (O2), capital (I1), labour (I2), materials (I3), services (I4) and rainfall (I5)) are described in Appendix one. 5. ResultsThe inclusion of rainfall as a non-discretionary input variable ensures that no farm is compared to another with a higher level of rainfall (i.e. with a more favourable environment). The impact that this has on TE is displayed in table 2, where the TE distributions and mean scores from both the conventional and rainfall-adjusted DEA models are compared in each of the three years. Table 2 Conventional and rainfall-adjusted TE distributions
As described in section 3, TE scores from the rainfall-adjusted model should be greater than or equal to those from the conventional DEA model. The results presented in table 2 demonstrate this, with the mean TE scores from the rainfall-adjusted model being higher than those from the conventional model in each year. The inclusion of additional variables raises the overall dimensionality of the estimation problem, which can only cause the TE of some farms to remain the same and of others to increase. A number of farms that were inefficient in the original model improved their relative position because they were efficient in their use of rainfall. For example, in 1997 the conventional DEA model identified 33 efficient farms, but when the rainfall-adjusted model was used a further nine farms were also found to be efficient. After the inclusion of rainfall as a production input the TE distributions in each year became more skewed towards the higher efficiency ranges. Perusal of table 3 reveals the extent to which TE scores changed according to annual rainfall. As expected, farms with the lowest levels of annual rainfall experienced the greatest increase in TE after incorporating rainfall into the production function. On the other hand, most of the farms with greater than mean rainfall did not experience an increase in TE. This approach, unlike the two-stage regression approach discussed in section 2, does not penalise farmers with more favourable environments by reducing their TE scores. Rather, it rewards farms with unfavourable environments by increasing their scores by greater amounts than those with favourable environments. Table 3: Changes in TE according to variations from mean annual rainfall
While the changes in TE distributions and scores provide useful information on the effect of incorporating rainfall into the production frontier, the changes in the relative rankings of the farms are more important. If farm rankings between the rainfall-adjusted and conventional TE series are significantly different, then it can be concluded, unequivocally, that failure to account for variation in annual rainfall lead to an incorrect assessment of each farm’s relative performance. Spearman coefficients of rank correlation were used to test the following hypothesis: H0: rs = 0, i.e. there is no significant correlation between the conventional and rainfall-adjusted TE efficiency rankings H1: rs ≠ 0, i.e. there is significant positive correlation between the conventional and rainfall-adjusted TE efficiency rankings According to the Spearman coefficients of rank correlation (table 4), there is very significant rank agreement between the conventional and rainfall-adjusted TE rankings in all years. Hence, in this case, it is concluded that failure to account for farm variation in rainfall did not confound the identification of meaningful rankings. Table 4 Rank agreement between TE and rainfall-adjusted TE series
a denotes t-statistics significant at the 1 per cent level of significance. In this instance the variation in rainfall across farms in each year was probably not large enough to significantly affect the relative rankings of the sample farms. While these findings may bring some comfort to those that have investigated farm efficiency without accounting for variations in rainfall, it is still recommended that rainfall be included in the production function in order to provide more accurate TE measures. In many cases variations in farm rainfall will be large enough to influence farm efficiency rankings. Moreover, even when they are not DEA models that ignore rainfall variations may still report misleading targets for reducing inputs when calculating TE. To illustrate this point consider farm 14 which received only 312 mm of annual rainfall in 1997, more than 100 mm below the average for that year. The conventional DEA model, which compares this farm to others with both higher and lower levels of rainfall, gave this farm a TE score of 0.785. However, when this farm was compared only to those with a level of rainfall less than or equal to its own level, the rainfall-adjusted DEA model reported a TE score of 0.960. When the farm’s low level of rainfall is ignored, the conventional DEA model reports that farm 14 must contract its input usage by (1-0.785)*100 = 21.5 per cent in order to become efficient. Yet when the farm’s low level of rainfall is accounted for, a considerably more modest contraction of (1-0.960)*100 = 4 per cent is reported. A weaknesses inherent in the method chosen for this study is that it restricts the size of each farm’s reference set, slightly inflating TE scores and raising the number of fully efficient farms. While this may be a shortcoming of the single-stage method, the exclusion of rainfall from the model would be more difficult to justify. Because rainfall is so vital to farm production in dryland farming systems, omitting rainfall has the potential to invalidate a DEA study of dryland agriculture. In effect, rainfall on each farm in each production year typifies a state of nature that greatly affects production outcomes. A low TE measure may simply be attributable to that farm’s state of nature rather than a farmer’s inability to best manage inputs. Another possible weakness of this study relates to use of annual rainfall data rather than growing season rainfall (May to October). Because approximately 75 per cent of annual rainfall falls in the growing season in the study region, the impact of rainfall on TE may have been more appropriately captured if rainfall only in, and perhaps just prior to[5], the growing period was considered. An even better measure, if available, would have been soil moisture content, because this more accurately reflects crop moisture availability. Future studies could address these weaknesses, especially where appropriate rainfall and soil quality data are available. 6. Conclusions and CaveatsThis study reports farm-level technical efficiency measures which account for variations in farm annual rainfall by including rainfall as a non-discretionary production input in an input-orientated DEA model. This ensures that farms are only compared to those with lower or equal annual rainfall. The results demonstrated that if rainfall differences are ignored, more farms are deemed to be inefficient. However, including rainfall differences raises the number of fully efficient farms and the TE level of many less efficient farms. Hence, failure to include the effects of rainfall differences will bias estimates of farm technical efficiency and could potentially lead to poor management or extension advice to farmers. Spearman coefficients of rank correlation were used to test whether the farms' performance rankings, before and after accounting for rainfall, were significantly different. In this study it was found that failure to account for variations in annual rainfall did not significantly bias the relative performance of the farms. This was partly attributed to a lack of variation in annual rainfall between farms. Despite this similarity between farm rankings, it is still recommended that rainfall be included in a DEA model, if possible, otherwise excessively optimistic performance targets may be reported. ReferencesABARE 1999, ‘Australian Grains Industry: Performance by GRDC agro-ecological zones’, Australian Farm Surveys Report, ABARE, Canberra, pp. 144. AWA 2000, ‘The Wheat Book: Principles and Practice’, Bulletin No. 4443. Agriculture Western Australia, pp. 322. Banker, R. D., Charnes, A. and Cooper, W. W. 1984, ‘Some models for estimating technical and scale inefficiencies in data envelopment analysis,’ Management Science, vol 30, pp. 1078-1092. Chapman, L., Roriguez, V. and Harrison, S. 1999, ‘Influence of resource quality on productivity of wool producing farms’, Australian Farm Surveys Report, ABARE, Canberra, pp. 37-41. Charnes, A., Cooper, W. and Rhodes, E. 1981, ‘Evaluating program and managerial efficiency: an application of data envelopement analysis to program follow through’, Management Science, vol 27, pp. 668-697. Coelli, T., Rao, P., and Battese, G. 1998, An Introduction to Efficiency and Productivity Analysis: Kluwer Academic Publishers. DAWA 1990, ‘Producing Lupins in Western Australia’, Bulletin 4179. Department of Agriculture, Western Australia, pp. 95. Dyson, R. G., Allen, R., Camanho, A. S., Podinovski, V. V., Sarrico, C. S., Shale, E. A. 2001, ‘Pitfalls and protocols in DEA’, European Journal of Operational Research, vol 132, pp. 245-259. Elteto, O. and Koves, P. 1964, ‘On a problem of index number computation relating to international comparison’, Statisztikai Szemle, vol 42, pp. 507-518 Farrell, M. 1957, ‘The measurement of productive efficiency’, Journal of the Royal Statistical Society, vol 120, pp. 253-81. Fraser, I., and Cordina, D. 1999, ‘An Application of Data Envelopment Analysis to Irrigated Dairy Farms in Northern Victoria, Australia’, Agricultural Systems 59: 267-282. Fried, H. O., Schmidt, S. S., Yaisawarng, S. 1999, ‘Incorporating the operating environment into a nonparametric measure of technical efficiency’, Journal of Productivity Analysis, vol 12, pp. 249-267. Henderson, B. B. 2002, Investigating the spread of efficiency amongst Western Australian broadacre farmers: a comparison between data envelopment analysis (DEA) and stochastic frontier analysis (SFA). Masters Thesis, University of Western Australia. O’Donnell, C.J. and Griffiths, W.E. 2005, Estimating state-contingent production frontiers. Paper presented to the 49th Annual Conference of the Australian Agricultural and Resource Economics Society, 9-11 February, 2005, Novotel Plaza, Coffs Harbour, New South Wales, pp. 31. Piesse, J., van Zyl, J., Thirtle, C. and Sartorius von Bach, H. 1996, ‘Agricultural efficiency in South Africa's former homelands: measurement and implications’ Development Southern Africa, vol 13, pp. 399-413. Piot-Lepetit, I., Vermersch, D. and Weaver, R. 1997, ‘Agriculture's Environmental Externalities: DEA Evidence for French Agriculture’, Applied Economics 29: 331-338. Rao, D.S.P. and Coelli, T.J. 1998, ‘Catch-up and Convergence in Global Agricultural Productivity, 1980-1995’, CEPA Working Papers, No. 4/98, Department of Econometrics, University of New England, Armidale, pp. 25. Szulc, B.J. 1964, ‘Indices for multiregional comparisons’, Prezegald Statystyczny (Statistical Review), vol 3, pp. 239-254. Appendix One: Description of the model’s variables and their derivationThe crops (O1) variable comprises an aggregation of the quantities of seven crop types: wheat, barley, oats, lupins, canola and other crops (such as faba beans and field peas). Even though the Fisher quantity index was used to aggregate these items, the corresponding values for each item were required to construct the index. The livestock quantity variable (O2) is an aggregate of sheep and cattle numbers and products sold. However, very few farms in the sample run cattle enterprises. Beginning with the sheep quantity variables, there are two different outputs: the first is sheep sold plus any positive change in the livestock inventory. The second is the quantity of wool produced in the production year. For cattle the only product is the number of cows sold. This output was computed in exactly the same manner as for sheep, i.e. numbers sold plus positive operating gains.[6] The capital variable (I1) is an aggregate of five items: land, buildings and structures, plant (machinery and vehicles), sheep and cattle. The first three of these five items were converted from stock into flow variables by calculating their user costs. These variables were converted into user costs simply by taking the average of their opening and closing values and multiplying this average by the market real rate of interest for that year. Thus the user cost could be interpreted as the cost to the farmer of not selling their on-farm assets and putting their money into a high interest savings account. The livestock inputs, sheep and cattle comprise two components. The first is purchases plus the absolute value of negative operating gains (i.e. when closing numbers less opening numbers is negative), which can be interpreted as capital stock depletion to produce output. The second component of the livestock inputs is their user costs that are calculated by multiplying the value of the opening numbers of livestock by the rate of interest for the relevant year. The quantities of livestock were also used to construct the index. The labour variable (I2) consisted of three items: operator/family labour, hired labour and shearing expenses. The farm records from which these variables were constructed contained information on the number of weeks worked by the farm operator and family members. The market rate for labour, obtained from ABARE farm survey results, was used as a notional price for operator/family labour. The numbers of weeks worked by hired employees was also recorded, along with money paid in wages for hired labour. Shearing expenses for each farm were taken from the farm financial records. Corresponding price indexes for each year were drawn from ABARE’s annual farm survey results to derive quantities. Materials (I3) is an aggregation of five items; crop chemicals, fodder and agistment, fertiliser, seed, and fuel. Only costs were available for these items, and once again the average price indices for these items were taken from ABARE survey results from WA broadacre farms and were used to obtain quantity estimates by deflating their respective costs. By applying an average price it was necessary, once more, to make the assumption that all the items were of equal unit value and of homogenous quality. Like materials, the items that make up services (I4) are only reported as costs on the farm financial records. The service cost items include: rates and taxes, administrative costs, miscellaneous livestock costs, total contract costs, total repairs costs, net insurance costs, other costs (e.g. general freight, fertiliser freight and spreading, electricity and gas). Again, average price indices were taken from ABARE WA farm survey results and quantities were obtained by deflating costs. Rainfall (I5), which is included as a non-discretionary variable in the second DEA model (equation 2), is measured in millimetres (mm) and includes total annual rainfall for each production year. Each farmer maintained records of monthly or annual rainfall received on their farm. [1] This computer program was developed by Tim Coelli, University of Queensland. [2] The rainfall variable (I5) is included as an input in the rainfall-adjusted DEA model only. [3] Coefficient of variation = (standard deviation / mean) * 100 [4]Computer program developed by Tim Coelli, University of Queensland, for calculating index numbers. [5] Rainfall from February to April also tends to boost yields, particularly on clay soils that can store water. [6] Where there were no sales, and hence no prices available for cattle and sheep, average State prices from the ABARE farm survey for that year were used. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Contact the University : Disclaimer & Copyright : Privacy : Accessibility |
|
Date Created: 03 June 2005 |
The University of Melbourne ABN: 84 002 705 224 
|